사람은 이미지를 볼 때 쉽게 이미지의 종(species)을 판단하는 것이 가능합니다. 물론 강아지같이 생긴 고양이를 보고 헷갈릴 수는 있겠지만요(..?).
이는 실제로는 인간의 뇌에서 고도의 연산이 일어나기 때문이며 컴퓨터는 이와같은 판단을 하는 것이 매우 어렵습니다. (Semantic gap)
다음의 고양이 사진을 볼까요? 컴퓨터의 언어로 고양이 이미지를 표현한다면 형태가 아닌 픽셀의 RGB(Red, Green, Blue)값으로 나타내야 합니다.

고양이의 목부분만 따서 살펴볼 때, 컴퓨터는 그림 1의 오른쪽과 같이 인식합니다. 이때 시점을 조금만 바꿔도 RGB 값의 차이가 생기기 때문에 다른 대상으로 판단하기 쉽습니다(마치 코끼리 다리를 만진 장님과 코끼리 귀를 만진 장님이 서로 다른 대상이라고 생각하듯이!). 따라서 상당히 많은 연산과정을 거쳐야 합니다. 뿐만 아니라 컴퓨터의 판단을 위협하는 다음과 같은 추가적인 방해 요소가 있을 수 있습니다.
1. 그림자
2. 다양한 형태
3. 은.엄폐
4. 보호색
5. 같은 종이어도 다양한 특징
이러한 많은 경우의 수를 모두 코딩 작업으로 해결하는 것은 불가능에 가깝겠죠? 따라서 사람들은 기계가 판단을 할 수 있도록 여러 방법을 고안했습니다. 머신러닝(그리고 딥러닝)의 목적은 컴퓨터가 최대한 인간의 사고에 가깝게 판단이 가능하도록 구현하는 것입니다.
Data Driven approach
우리가 원하는 것은 간단합니다. 고양이의 사진을 보여줬을 때, 컴퓨터가 print("고양이") 하는 것이죠. Data Driven Approach에서는 다음과 같은 과정을 거칩니다.
1. 이미지와 라벨을 수집한다.
2. 분류기(Classifier)를 학습시키기 위해 머신러닝을 이용한다.
3. 새로운 이미지를 분류기에 적용, 평가한다.
위의 과정을 보니, 분류기가 중요한 역할을 다하는군요! 그렇다면 분류기에는 어떤 종류가 있으며, 어떻게 동작할까요?
Classifier의 종류(Example Dataset : CIFAR-10)

NN(Nearest Neighbor)
간단히 설명하자면, NN은 모든 데이터셋을 기억하고, 새로운 이미지가 들어왔을 때 가장 유사한 training image의 label값을 출력합니다. 이때 모든 이미지를 단순 ‘기억’ 하기 때문에 학습에는 시간이 얼마 걸리지 않지만(Train O(1)), 비교 시TestData당 1: N(전체 데이터)의 비교 과정을 거치기 때문에 시간이 오래 걸립니다(Predict O(N)).
공식이 주어지는 문제집은 빠르게 풀지만 실제 시험에서는 이공식 저공식 다 넣어보며
1문제에 공식의 개수만큼의시간이 걸리는 학생이 있다고 생각해보자. 얼마나 비효율적인가!

컴퓨터는 이미지를 RGB 값의 조합으로 인식한다고 앞부분에 서술하였습니다. 이에 맞는 방식으로 두 이미지의 유사도를 판단하고 싶어 사용하는 것이 L1과 L2 distance입니다. NN에서는 그림 2와 같은 L1 distance(멘해탄거리)을 사용합니다. 이때 결괏값이 0에 가까운 training이미지의 라벨을 출력합니다.
KNN(K-Nearest Neighbor)
KNN은 몇 가지 개념을 잡고 가면 이해가 쉬울 것 같습니다.
1. Vote
2. Hyper Parameter
3. 데이터셋의 구성(Train, Validation, Test)
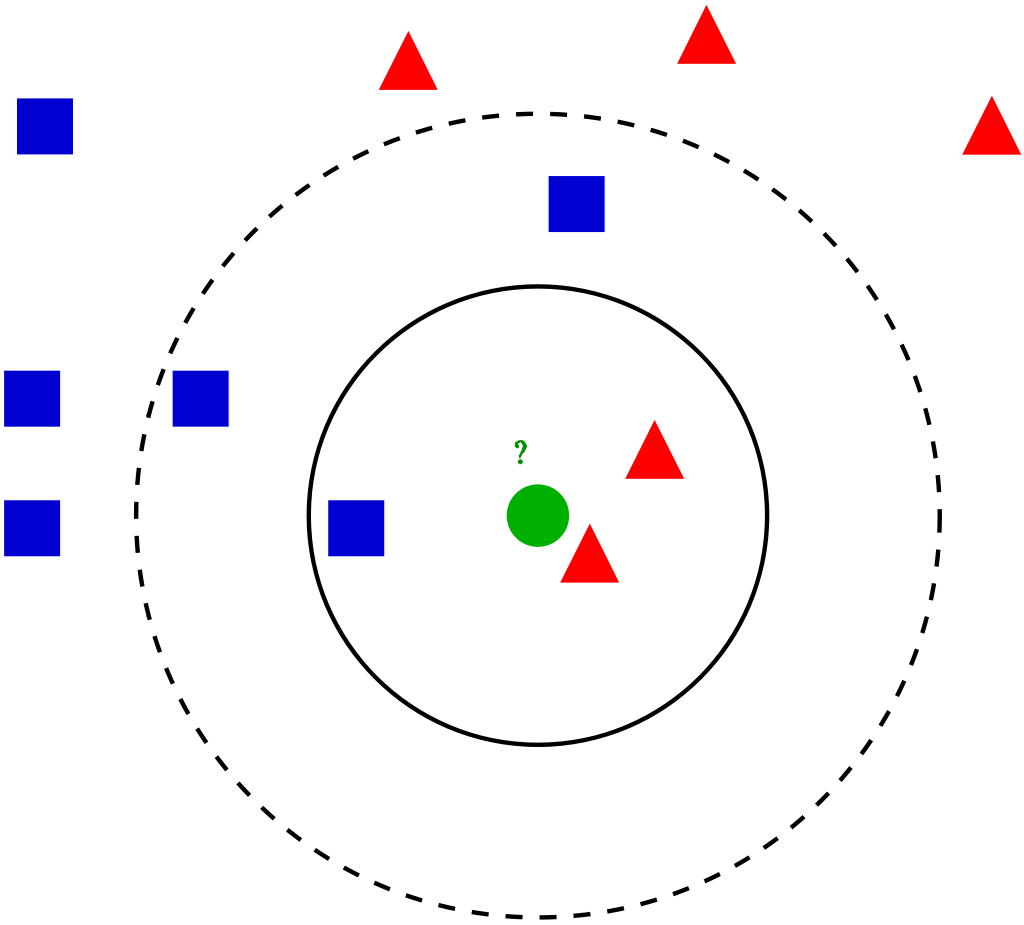
Vote
우선, KNN알고리즘은 민주적입니다. 이들은 투표에서 평등의 원칙을 지켜나갑니다. 좌표상에서 데이터는 점으로 나타납니다. 그림 4에서 보시는 것과 같이, 현재 우리가 알고 싶은 것은 초록색 원의 라벨입니다. K = 3일 때, 초록색 원은 빨강 세모의 라벨 값이 출력됩니다. 파랑은 한 표를, 빨강은 두 표를 행사하기 때문이죠. 그러나 K = 5일 때, 전세는 역전됩니다. 파랑은 세표, 빨강은 두 표가 되기 때문이죠. 이처럼 K값에 따라 우리가 알고 싶은 데이터의 라벨이 달라지게 됩니다. K값을 정하는 게 중요하다는 걸 아시겠죠?
Hyper Parameter(K, Distance Metric)
그렇다면 K가 뭔지 또 궁금해지지 않나요? 알아보도록 합시다. K는 특정 데이터를 판단할 때, 몇 개의 주변 데이터를 활용하여 해당 데이터를 판단하는지 정해주는 기준입니다. K개의 데이터 수를 기준으로, 범위 내에서 서로 투표하여 가장 많은 득표를 한 label을 해당 그룹의 label로 결정합니다. 이처럼 연구자가 원하는 결과를 도출하기 위해 결정하는 '기준'을 Hyper Parameter라고 합니다. 데이터 내부에서 도출되는 매개변수인 Parameter와는 다른 개념입니다.
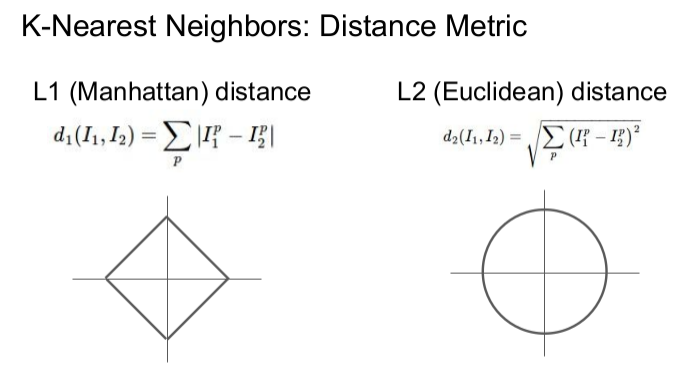
데이터 간의 거리를 계산하는 2가지 계산법(L1, L2)을 결정하는 것도 연구자의 소관입니다. 어떤 거리 계산법을 사용했을 때 성능이 좋은지를 판단하여 알맞은 방법을 선택해야 하죠. 이 역시 Hyper Parameter입니다.
(일반적으로 L2가 많이 사용된다고 합니다)
데이터셋의 구성(Train, Validation, Test)
이러한 판단은 데이터 의존적입니다. 그러나 주어진 데이터만 가지고 판단하는 것은 지나치게 주어진 데이터에'만' 최적화된 모델이 완성될 수 있습니다. 이를 오버 피팅(Over Fitting)이라고 합니다. 오버 피팅된 모델은 새로운 데이터가 들어왔을 때 이를 제대로 분류하지 못할 가능성이 있습니다. 그러나 우리의 목적은 모델의 일반화입니다. 따라서 주어진 데이터를 활용하여 여러 방법으로 검증을 거치게 됩니다.
주어진 데이터를 가장 잘 활용하는 방법은 train, validation, test 셋으로 구분하는 것입니다. train 셋에서 학습을 하고, validation 셋을 새로운 데이터로 활용하여 K를 정하는 등 해당 모델을 최적화합니다. test 셋이 남았군요.
test 셋을 활용하여 최적화된 모델을 검증합니다. 대신 연구윤리를 위해, 해당 과정은 단 1회의 검증으로 끝내는 것이 좋습니다. test셋을 몇 차례 활용하여 다시 최적화에 활용한다면, 이제까지의 일반화를 위한 노력이 의미 없어질 수 있습니다.
또 소수의 데이터셋에서 효과적인 Cross-Validation도 있습니다. 데이터셋을 비복원추출하여 K겹의 테스트 셋을 만들어 마치 여러 개의 데이터셋의 효과를 내는 거죠(대신 데이터의 양이 충분한 딥러닝에서는 거의 사용되지 않습니다. 의미가 없거든요).
자, 이제까지 KNN에 대해 길게 이야기해 보았습니다. 그러나 이미지 학습에서 이 방법은 거의 사용되지 않습니다. 테스트셋에서 너무 오랜 시간이 걸리고, 픽셀당 메트릭스 거리계산이 크게 유의미하지 않거든요. 추가적으로 차원의 저주도 계산을 어렵게 만듭니다.
요약하자면
이미지학습에서 training set의 이미지와 라벨을 활용해서
test set의 라벨을 예측하는 것이 목표입니다.
KNN분류기는 test 데이터를 가까운 training 데이터에 근거하여 분류합니다.
Distance Metric과 K는 Hyper Parameter입니다.
Hyper Parameter는 Validation set을 활용하여 선택하고,
최후의 최후에 test set을 활용하여 딱 한번! 검증합니다.
길고 재미없는 글 읽어주셔서 감사합니다. 저도 처음 들어본 어려운 내용이라 틀린 부분이 많을 것 같습니다. 혹시 잘못된 내용이 있다면 댓글로 알려주시기 바랍니다. 감사합니다.
해당 글은 스탠퍼드 대학의 CS231n(Convolutional Neural Networks for Visual Recognition)을 정리한 글임을 밝힙니다.
'Note' 카테고리의 다른 글
| DEEPML(CS231n) Lec.04_1 Backpropagation (0) | 2021.01.25 |
|---|---|
| DEEPML(CS231n) Lec.04_1_1 What is backpropagation really doing? (0) | 2021.01.24 |
| DEEPML(CS231n) Lec.03_2 Optimization (0) | 2021.01.22 |
| DEEPML(CS231n) Lec.03_1 Loss Function (2) | 2021.01.10 |
| DEEPML(CS231n) Lec.02_2 Linear Classification (0) | 2021.01.04 |